Unadversarial Point Cloud
We aim to augment the performance of NN by utilizing gradient-guided data-augmentation(*unadversarial learning*) method.
In the implementation, we use the common way of generating the adversarial example, utilizing methods such as FGSM/PGD to derive the gradient on the input then update the input by back propagation.
the primary experiment to verify the unadv process in the object-level point cloud:
Background
In the past, it was common to use gradient to modify input examples mostly to generate Adversarial Examples (AEs), i.e., to maximize target loss under certain restrictions (e.g., changes should be invisible to human eyes) to achieve an attack against a certain task, called Adversarial Attack.
An article from NeurIPS 21’ tried something special:
They try to modify the inputs in simulated and realistic environments using the “unadversarial” approach to make it easier for the model to classify/detect the target object.
It prompts us to consider whether this process can help us to achieve more robust objects, or to defend adversarial attacks?
Motivation & Story
In the previous discussion, we discussed about two general directions:
- (Theory Track)To study/verify the relationship between adv ↔ unadv to see if we can get some insights, which is closer to studying theoretical adversarial robustness.
- (Application Track) To find applications of unadv in real-life scenarios, referencing
to find scenarios where there may be applications in real world to design simulated/realistic robust objects (for vision models).
Theory Track
In the direction of theoretical research, we can explore the relationship between adv and unadv.
Q1:
A1:
It’s possible.
In this paper, they found that adv attack increased the embedding distance of the image itself in the contrastive embedding hyper-space, so using self-supervised contrastive optimization for the input image that may be attacked can be defensive. This illustrates that adversarial attack can be defended by some form of reverse adv (e.g. self-supervise) .
In another article:
The authors argue that adv/unadv is itself symmetric.
Q2:
A2:
We can start with a study on transferable adv attack, from a paper that has been rejected by ICLR22.
From this article we can get some insights that if the adv example is restricted to the region where the loss does not vary drastically, the transferability of attacks may be boosted.
The theory may also be explained in terms of the difficulty of unadv.
less reversible adv example = adv example at flatter regions of loss. If unadv was performed at flatter region, it is also difficult to perform unadv perturbations(since the gradient value is tiny).
On the flip side, if unadv is performed at flatter loss regions, then it is less likely to be attacked.
Q3:
A3:
Don't have much idea at the moment. Need to think about ways to implement adv/unadv that can break this cycle and maybe guide us to come up with new attack methods.
Additions
Adi Shamir gave a keynote speech titled "A New Theory of Adversarial Examples in Machine Learning" to explain his latest published work. In this talk, he proposed a "dimpled manifold" to explain the nature of adversarial examples in machine learning, providing a new way of thinking about how deep neural networks work, which is groundbreaking for the field.
https://arxiv.org/pdf/2106.10151.pdf
The first stage is the rapid formation of decision boundary, which is the process of quickly getting the decision boundary close to the image manifold, corresponding to the rapid decline of the loss at the beginning of training. The second stage is "hammering", i.e., hammering on the manifold for some “slots” to a certain class.
If the rapid decline of loss at the beginning is to produce a smooth manifold in the high-dimensional place for decision boundary, then the later training is like a small knock on this manifold to do some slots for fine tuning.
That is why it is easy for adv examples to jump out some slots with small changes under the gradient guidance.
Application Track
In the direction of application research, we can try to use unadv to generate robust objects to improve the performance of downstream tasks.
Q1:
A1:
- Robust tags for robotics
April Tag, widely used in robotics, is detected under a fully rule-based recognition process.
Its performance will degrade under fisheye lenses.

Task:Optimize correspondence for input
Is it possible to add the unadv pattern to the April Tag to make the identification process easier?
new image pattern vs April Tag (in distortion/low-res/side-view/high-contrast/very-close distance)
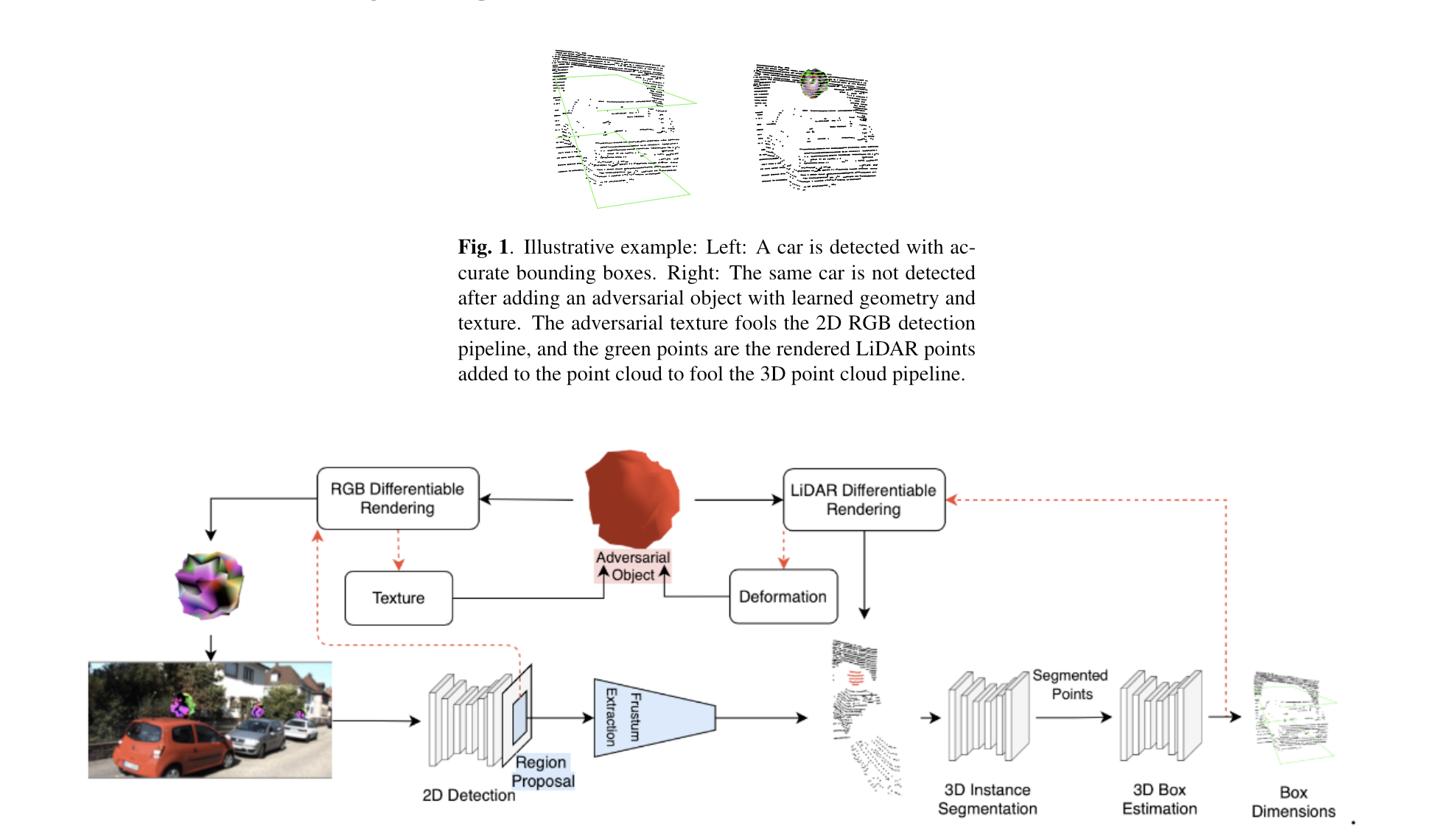
- Robust stickers/objects for autonomous driving
In past papers, there are attempts to 3D print in virtual space/realistic scenes to generate adversarial object to jeopardize object detector, the same set can be given to unadv to try: can we generate unadv stickers (this is almost done in this article mentioned before, we can add some constrains to make it look more fancy or realistic); or render an unadv object on the car, making it easier to be detected, these two should be more feasible direction.